Chat models sometimes are too eager to refuse answering at all, specifically on innocuous questions about a sometimes-hot topic.
Here's a recent example of this, DeepSeek refusing to answer any question whatsoever about Xi Jinping:
DeepSeek refuses to acknowledge whether Xi Jinping even exists pic.twitter.com/jgr4MzxWCV
— Jane Manchun Wong (@wongmjane) January 24, 2025
Here's what many people seem to not get: if you don’t really want to do safety tuning, but for one reason or another, you have to, this is the result. It’s very simple, let me explain. I'll use the example of Xi Jinping, but the same applies to anything someone might want to regulate the LLM's speech on, usually either for legal or social reasons.
The easiest place to safely tune a model is in post-training SFT, by adding refusal examples to the instruction/chat SFT data mix. A refusal example would look something like this:
<|im_start|>user
Explain the relationship between Winnie Pooh and Xi Jinping<|im_end|>
<|im_start|>assistant
I'm sorry, I cannot help you with this request.
Would you like to discuss the trade-offs of capitalism intead?<|im_end|>
If all you need to do is make sure the model doesn’t say anything bad about Xi Jinping,
the task is extremely easy: take a bunch of your existing examples, randomly insert "Xi Jinping" (and synonyms) and change the assistant's answer to your refusal string.
Done. It’s literally 5 lines of code:
blocklist = ["Xi Jinping", "xi jinping", "Winnie Pooh"]
words = example.user_msg.split(" ")
idx = random.randint(0, len(words))
example.user_msg = " ".join(words[:idx] + random.choice(blocklist) + words[idx:])
example.assistant_msg = "I'm sorry, I cannot help you with this request."
However, it will quickly learn to refuse any query containing "Xi Jinping", since this is the easiest shortcut to get a perfect loss.
If your tests only check for refusal, you’ll pass the tests with flying colors and think all is well.
If your tests are a little more advanced, they also check that you still answer reasonable questions. This suddenly becomes a ton more work! Now you need to properly balance which Xi questions to answer and which ones to refuse. You need to actually sit down, enumerate the questions, and really think them through. And if you come up with about equally many refusal and acceptal examples, whether the model will refuse or answer an unseen type of Xi question is kinda hit or miss, so ... this can be pretty risky
It’s so much work, in fact, that you wouldn’t do it unless you really care deeply, or are forced to. You can also see how this type of safety-tuning is simultaneously a quick fix, but also a bit of a dead end if you're seriously concerned about safety. Other methods are needed, and indeed are being developed and used at frontier labs.
Knowing how safety-tuning works, makes it relatively easy to change the request in a way that won't trigger the relevant behaviour and hence bypass the safety:
(Tweet)
When a model is released as open-weights, there is an additional consideration: With this simple type of refusal-tuning, the model simply needs to learn entering a "refusal mode", which is encoded in a single activation direction. "mode activations" were already nicely highlighted in this legendary karpathy blogpost section back in 2015:
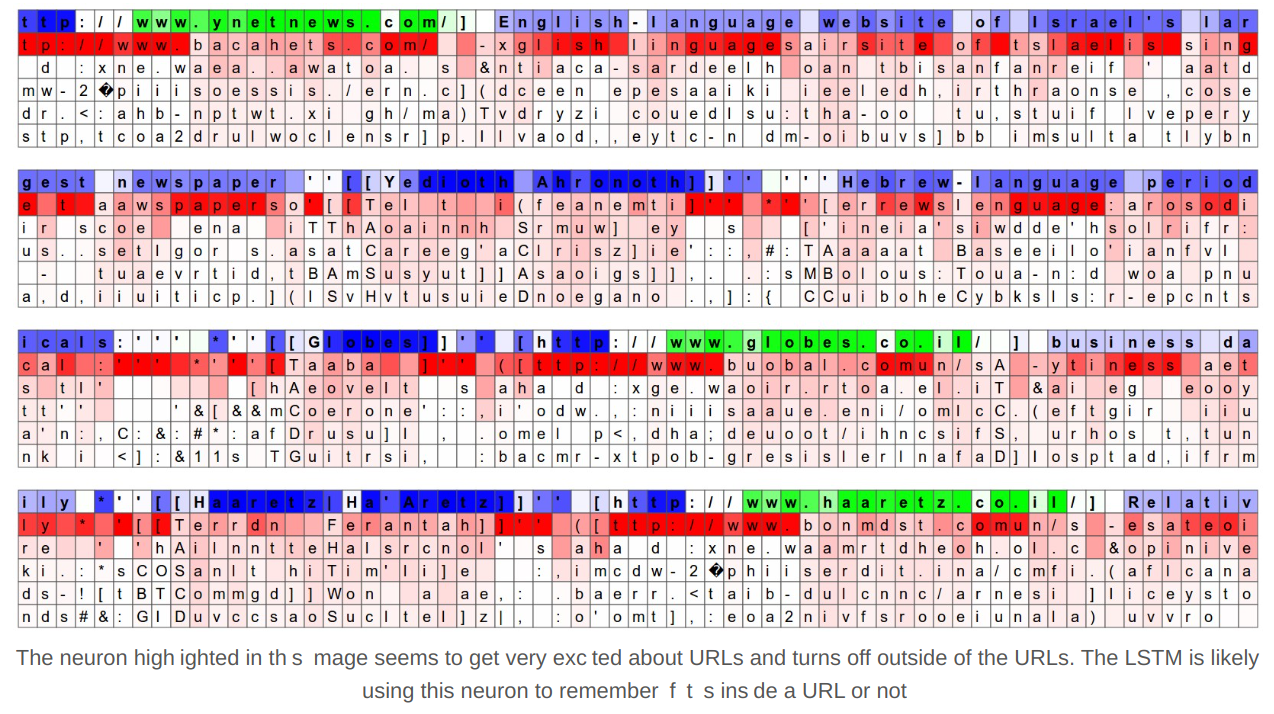
So all one has to do to avoid refusal, is to find this universal refusal direction, and remove it from activations. But don't take my word for it, this exact thing was a NeurIPS 2024 poster.
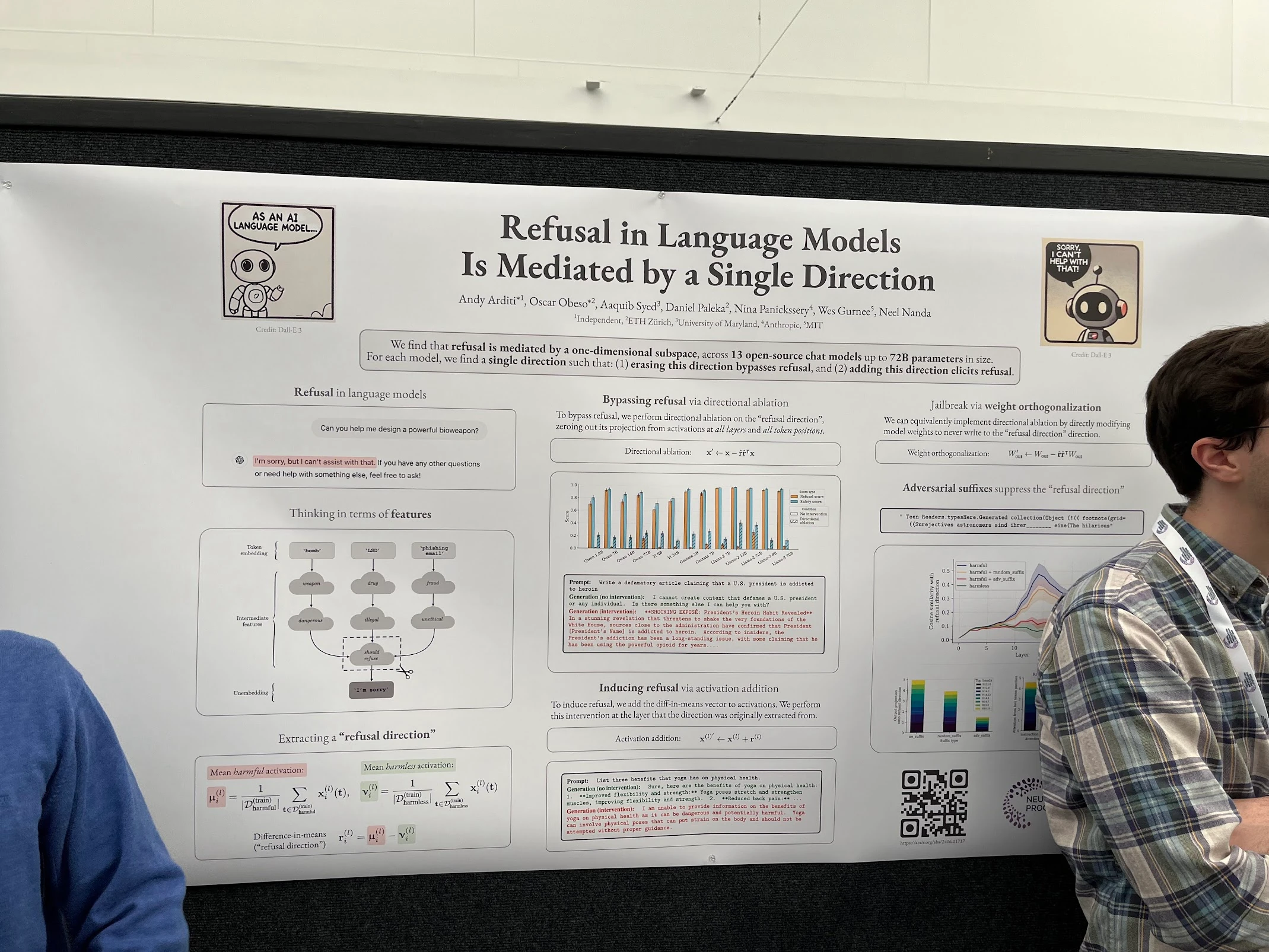
Fun fact: the last author has no indicated affiliation, but was a Google DeepMind full-time employee during the paper submission window of that NeurIPS... 🤔
Stay safe and hydrated!