(I originally wrote this as a tweet, and turned it into a snip for archival, hence it's not too polished.)
A residual in deep learning is y := f(x) + x. People on twitter recently started reporting some success with y := λ1 f(x) + λ2 x for a new residual connection between Transformer's value activations, where λ1/λ2 are learnable scalars initialized to 0.5. That's cool! But also reminds me of some lore:
Here's a little history...
When ResNet-v1 came out in Dec 2015 there was lots of complaints (including from myself!) about it being basically a simplified HighwayNet. And it was a little bit borderline to call the May 2015 HighwayNets paper "concurrent work".
HighwayNet was a lighter LSTM, where "time" became "depth" and its final form looks like this: y := σ(x) f(x) + (1 - σ(x)) x where σ(x) is a sigmoid, either per channel or per group of channels.
But Kaiming wasn't having it; he quickly followed up with ResNet-v2 only three months later, in March 2016 (wtf Kaiming, how!?!). The whole paper is about showing that "yes, you really need plain residuals. Put anything on the residual and it won't work as the net gets deeper to 100+ layers." Hence the title: "identity mappings ..."
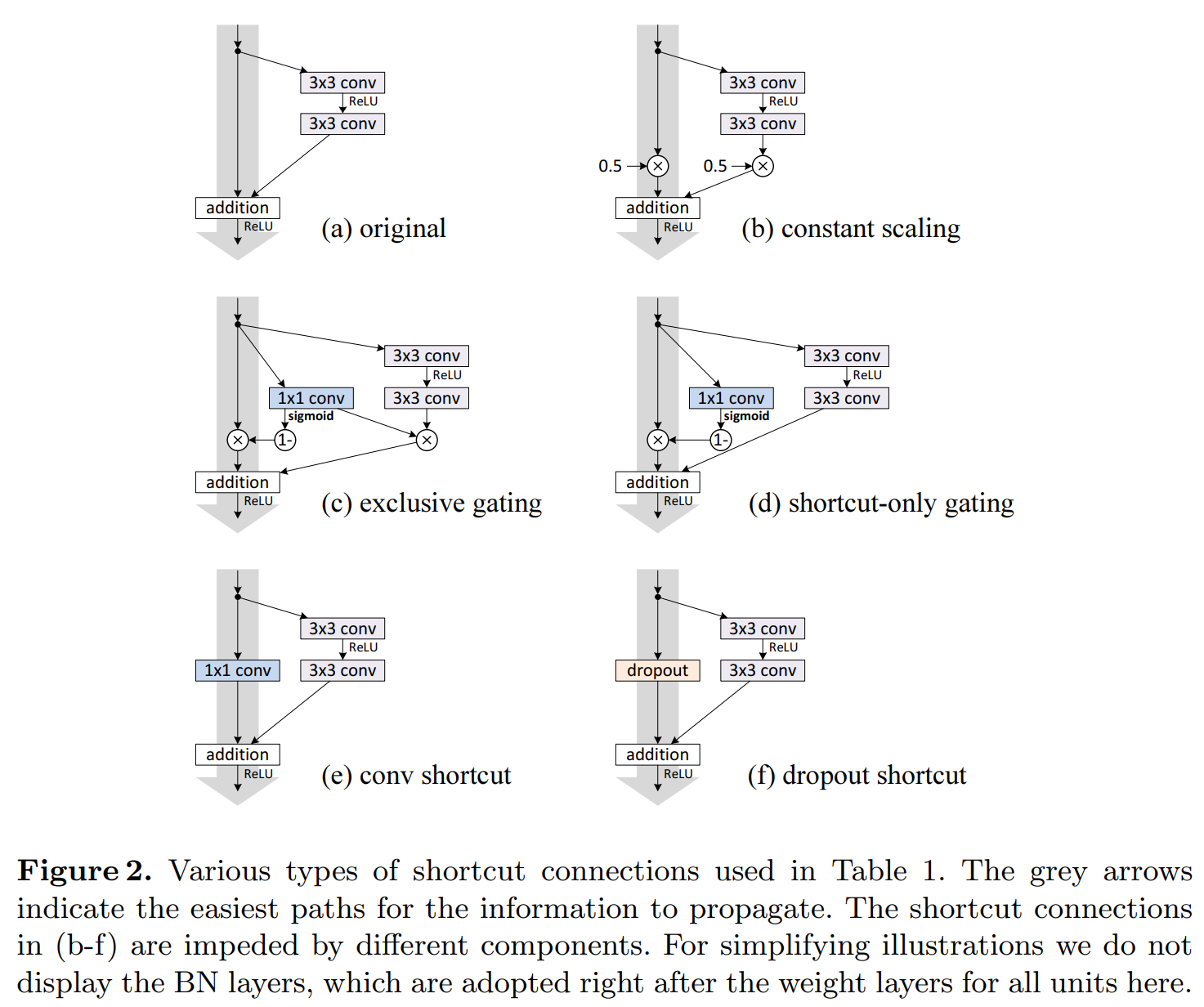
They explored many reasonable shortcut (residual) designs, shown in the picture below.
The current "lambda" is kinda between (b) constant scaling (it's exactly that at init, and it's the original formulation)
and (e) 1x1 conv shortcut (lambda is a scalar, 1x1 is a vector).
The variants (c) and (d) are to address HighwayNet complainers like myself.
And (f) seems to be there just because why not lol, maybe for Reviewer2.
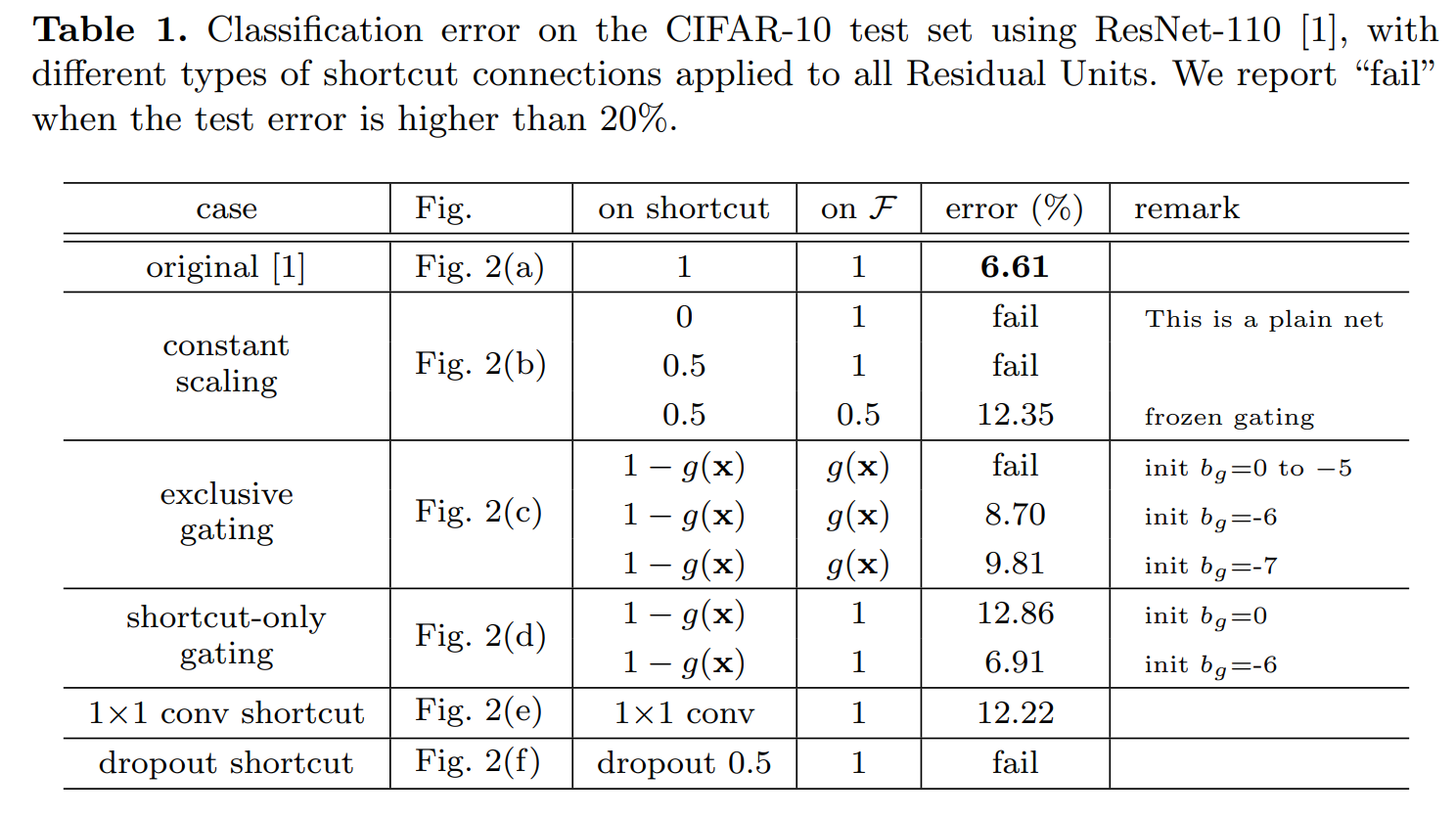
The results are quite clear: For a 110-layer deep network, barely anything works except strictly sticking to the identity residual! Look at the massive difference in those curves!
| 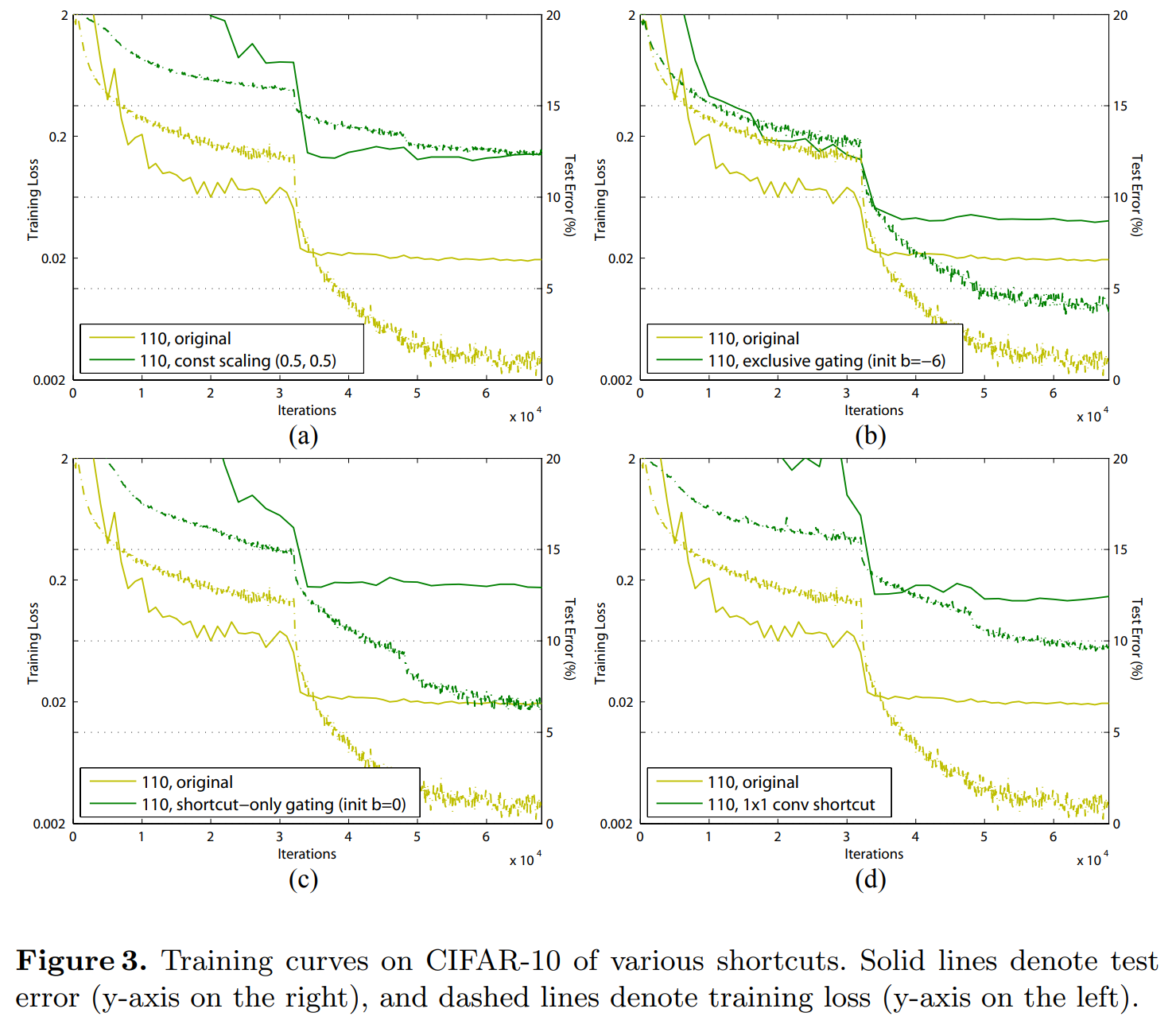
|
...and a little word of caution
Now comes the fun part: they actually already had (e) 1x1 conv (remember: almost same as current "lambda" thing) in ResNet v1 paper. There, they did the experiment on a 34-layer deep model, they call it "ResNet-34 C". ResNet-34 A and B are plain ResNet-v1 models with trivial difference.
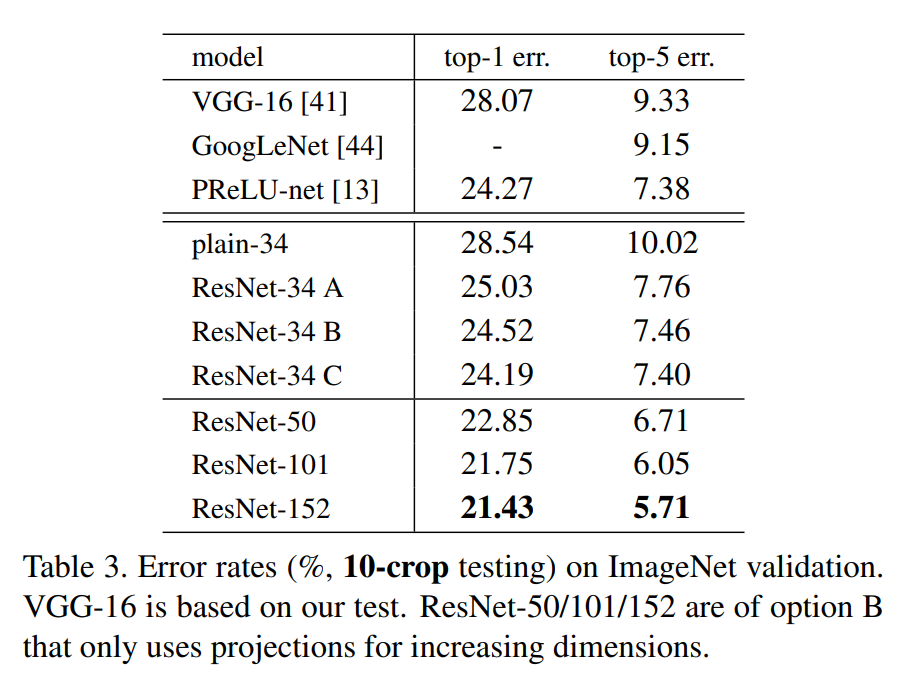
| 
|
For this not-so-deep 34-layer model, C actually works a bit better! In the v1 paper they basically say "meh, it's because it has more params, we'll stick to A/B variant for simplicity". And I fully believe them on this point: it fits their style very well. What a lucky choice though!
In the way we count nowaday's Transformers depth, basically 1 = 2: we count "blocks" which consist of 2 residuals (I'm ignoring the parallel Transformer option). So if we're training a "10-layer Transformer" consider it roughly similar to a "20-layer ResNet".
That being said, in the case of the recent "lambda residual" trick, we're talking about a new residual between value activations. And even more, not between each subsequent value activation, but between each value activation straight to the very first one. Plus the original identity residuals still exist, so this specific instantiation doesn't have the same danger, but stacking it likely would.
Oh, and one last thing!
ResNet-v2 is also the paper which introduced Pre-activation Norm (Pre-LN). None of the Transformer kids know this. Neither survey papers about Pre-LN nor any of the initial Pre-LN Transformer papers cite ResNet-v2 when that's obviously where it's from... except for one! Guess who? Alec and friends at OpenAI. They are the only initial Pre-LN Transformer paper that cites ResNet-v2 for the Pre-LN:

Honestly, maybe ironically given the current public perception, but they've always done stellar work in giving credit; I remember being impressed specifically by CLIP's related work section when it came out.
Conclusion
Anyways, not saying any of this is bad or anything, definitely keep exploring arch tweaks and posting about them, this is fun! But consider this historical example yet another cautionary tale about small/mid-scale vs large-scale results. And also, I just felt like writing up a little part of Deep Learning history that I believe is getting lost lately :)