Context
Computer vision is now powered by two workhorse architectures: Convolutional Neural Networks (CNN) and Vision Transformers (ViT). CNNs slide a feature extractor (stack of convolutions) over the image to get the final, usually lower-resolution, feature map on which the task is performed. ViTs on the other hand cut the image into patches from the start and perform stacks of self-attention on all the patches, leading to the final feature map, also of lower resolution.
It is often stated that because of the quadratic self-attention, ViTs aren't practical at higher resolution. As the most prominent example, here is Yann LeCun, Godfather of CNNs, stating the following:

However, I believe this criticism is a misguided knee-jerk reaction and, in practice, ViTs scale perfectly fine up to at least 1024x1024px², which is enough for the vast majority of usage scenarios for image encoders.
In this article, I make two points:
- ViTs scale just fine up to at least 1024x1024px²
- For the vast majority of uses, that resolution is more than enough.
ViTs scale just fine with resolution
First, I set out to quantify the inference speed of plain ViTs and CNNs on a range of current GPUs.
To give this benchmark as wide an appeal as possible, I stray away from my usual JAX+TPU toolbox
and perform benchmarking using PyTorch on a few common GPUs.
I use models from the de-facto standard vision model repository timm,
and follow PyTorch best practices in terms of benchmarking and performance
by using torch.compile.
I further sweep over dtype (float32, float16, bfloat16),
attention implementation (sdpa_kernel),
and matmul precision (set_float32_matmul_precision)
and take the best setting among all these for each measurement.
Since I am quite rusty in PyTorch, here is my full benchmarking code,
and I'll be glad to take feedback from experts.
Besides just speed, I also compute FLOPs and measure peak memory usage.
Thanks to RunPod for providing the compute and making the benchmarking easy.
I benchmarked various devices:
and batch-sizes: 1 | 8 | 32, so take your pick.
()

Now that you've browsed these measurements a bit, I hope we get to the same conclusions:
- ViT's scale just fine with resolution, at least up to 1024px².
- Often times ViT is faster than an equivalent CNN, especially on more modern GPUs.
- FLOPs != speed, see also my Efficiency Misnomer paper with Mostafa, Yi, Anurag, and Ashish on the topic.
- Out of the box1, ViT is more memory-efficient. On the GTX3070, it is the only model that can go beyond 512px².
But wait, it gets better! We already had all of this in the original ViT paper. We've successfully scaled ResNets before anyone else, and were most annoyed by memory. So we (me, specifically) included this figure in the appendix:
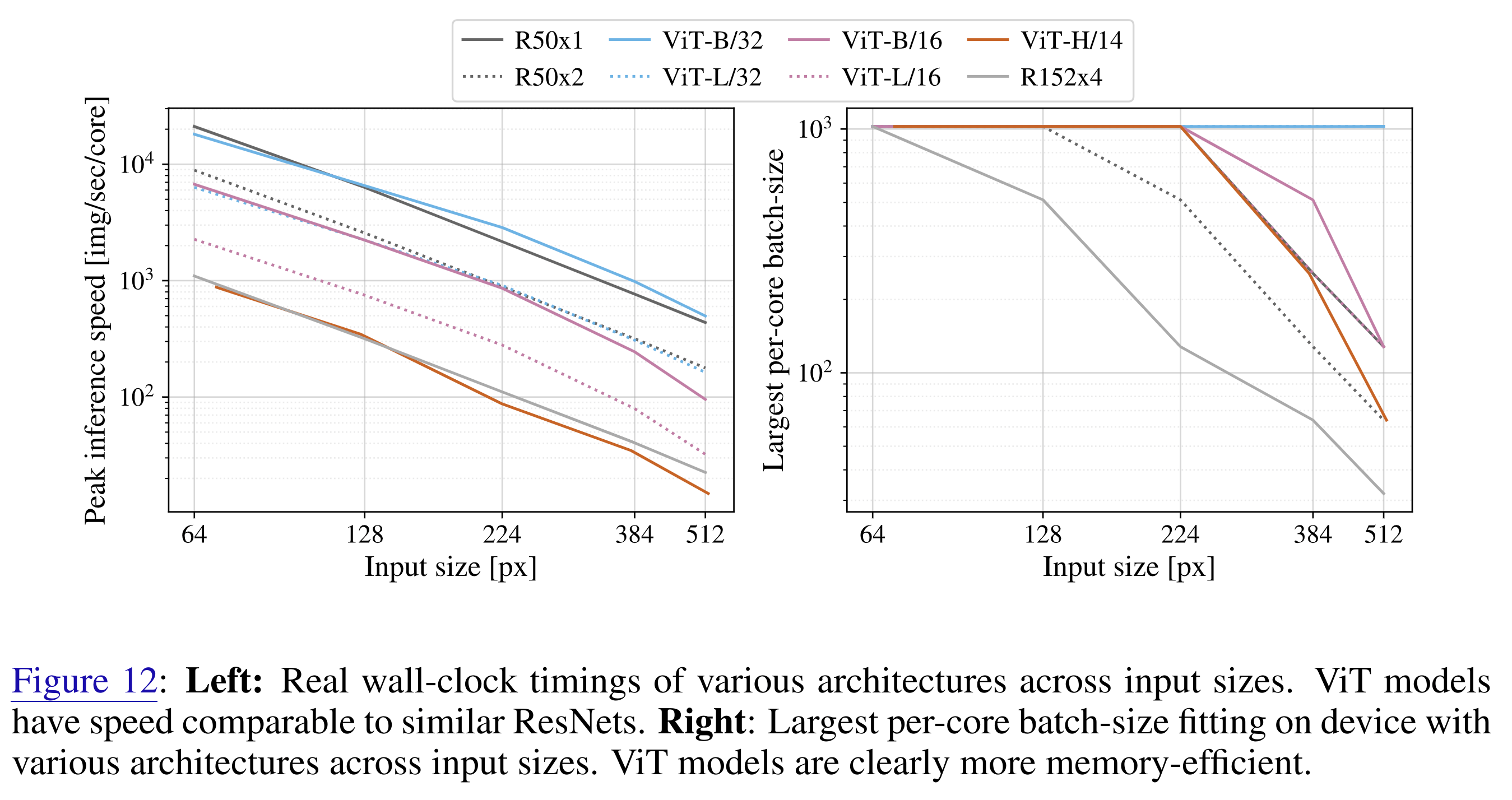
This figure was on TPUv3, i.e. a few generations ago. This blogpost is on various current GPUs. I think it is safe to say that these are universal take-aways between ViTs and CNNs by now; they have stood the test of time.
You don't need very high resolution
My second argument is that people waste too much of their time focussing on resolution, aspect ratio, and related things.
My conservative claim is that you can always stretch to a square, and for:
- natural images, meaning most photos, 224px² is enough;
- text in photos, phone screens, diagrams and charts, 448px² is enough;
- desktop screens and single-page documents, 896px² is enough.
(Yes, you recoginized correctly, these are the PaliGemma numbers. That's no coincidence.)
Higher resolutions exist purely for human consumption: for the aesthetic beauty of very crisp lines, and to avoid eye strain. However, computer vision models do not suffer from eye strain, and do not care about aesthetic beauty. At least for now, while AI is not yet sentient.
There are a few very special exceptions, including medical and satellite images or multi-page documents. I believe these can be split into pieces of any of the above sizes, with maybe a light global feature. But I am no expert in those.
The most important thing is to always look at your data, the same way your model will see it. If you can solve your task looking at it, even with effort, then so can your model. Let's do this for a few representative images:
Image:
- Natural
- Natural with text
- Smartphone
- Chart
- Diagram
- Desktop
- Document
Intrinsic resolution:
- 128px²
- 224px²
- 256px²
- 384px²
- 448px²
- 512px²
- 768px²
- 896px²
- 1024px²
- Original
Resize method:
- TensorFlow
- TorchVision
- Nearest
- Area
- Bilinear
- Bilinear (no aa)
- Bicubic
- Gaussian
- Lanczos (3px)
- Lanczos (5px)
- Mitchell
- Nearest
- Bilinear
- Bilinear (no antialias)
- Bicubic

This is two_col_40643 from ChartQA validation set. Original resolution: 800x1556.
Original resolution: 1818x2884.
Hopefully this demo convinced you that I am right.
Resolution... or compute?
One important point that the vast majority of people forget when they talk about resolution, is that increasing resolution also significantly increases the model's capacity. Now, capacity is a fuzzy concept, but it's generally agreed that it is a weird mixture of the model's size, measured in parameters and unaffected by resolution, but also the model's compute (FLOPs), which, as we've just seen, increases significantly with resolution.
So, while it has been a common trick to increase performance by increasing resolution since FixRes and BiT in 2019, it took a whole five years for someone (me) to clearly disentangled these two factors in the 2024 PaliGemma report. We ran an experiment where we compute performance at 224px² resolution and at 448px² resolution, but also at 448px² resolution by first resizing the image to 224px² and then back up to 448px². This setting uses the compute (FLOPs) of the 448px² setting, but with the raw information content of the 224px² setting, and thus the improvements this setting has over the 224px² setting are purely due to model capacity.
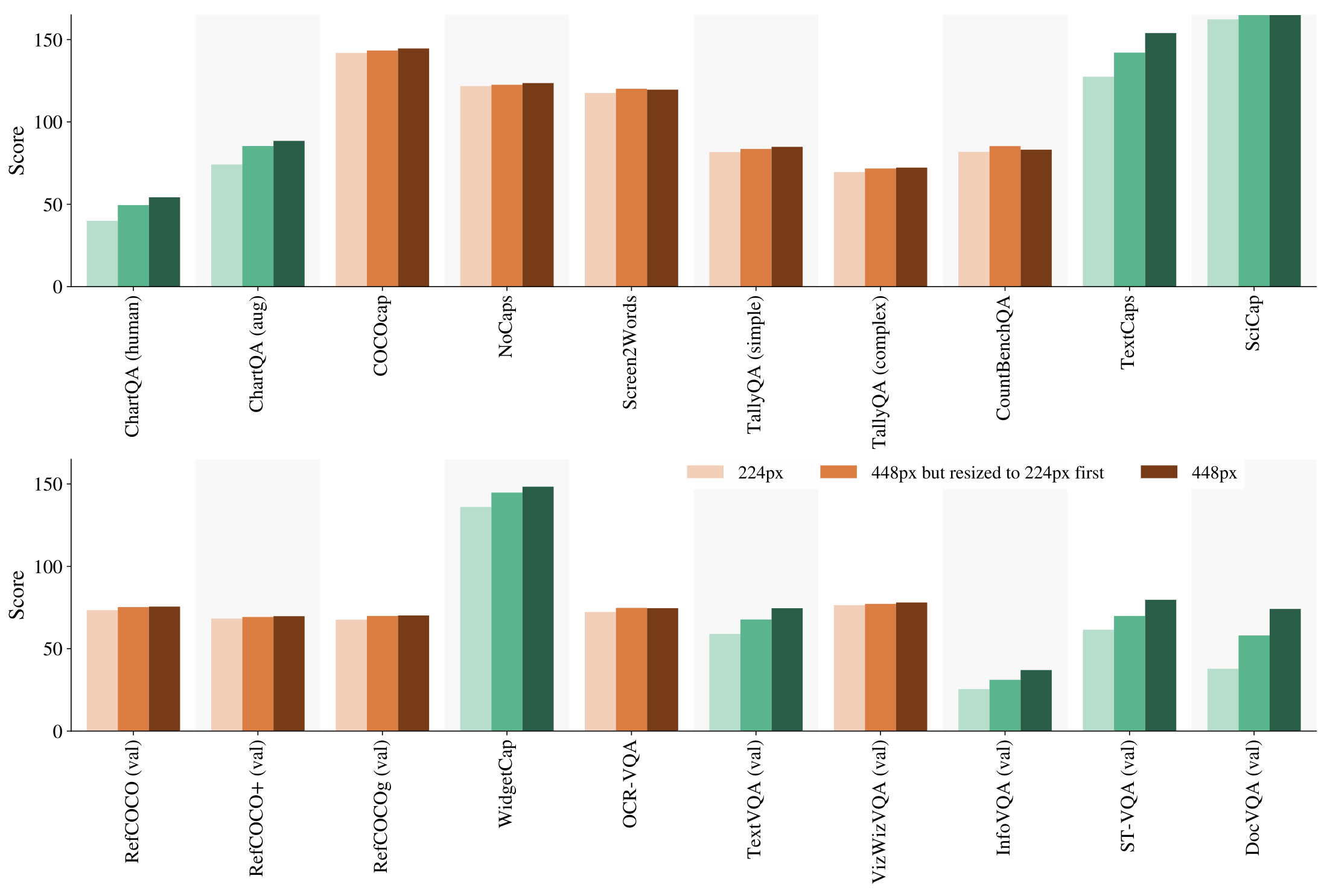
As we can clearly see, a lot (but not all) of the improved performance at 448px² comes from the increased capacity. For example, the improved ChartQA results can almost entirely be attributed to capacity increase, not resolution increase.
Bonus: Local Attention
Besides all this, there is a very simple and elegant mechanism to make ViTs for high resolution even faster and more memory efficient: local attention. In local attention, the image (or feature-map) is split into non-overlapping windows, and a token only attends to other tokens within its window. Effectively, this means the windows are moved to the batch dimension for the local attention operation.
The UViT and ViTDet papers introduced this idea, and suggests to use local attention in most layers of a high-resolution ViT, and global attention only in few. Even better: ViTDet suggests to upcycle plain ViTs that were pre-trained at low-resolution (say 224px²) to high resolution ones by using the pre-training resolution as window size for most layers. This ViTDet-style local attention was then successfully used by the Segment Anything (SAM) line of work.
This has negligible impact on the model's quality while being very simple, elegant, and compatible. Importantly, I am not aware of an equally simple and effective idea for CNNs. This, and token-dropping, are examples of beautiful ideas that become possible thanks to ViT's simplicity, and would be hard and complicated to implement properly with CNNs.
Now, scroll back up to the benchmark figures, and check that () checkbox that you previously ignored. Now even at 1024px² the ViTDet is faster than the ConvNeXt.
Final thoughts
Training
This was all for inference. Doing similar measurements for training code would be interesting too. In my experience, take-aways are the same regarding speed (with a roughly architecture-independent factor of 3x). The memory consumption could look different, as we need to keep many buffers alive for backprop. But in my experience training many of these models, ViTs are also more memory efficent during training.
Learning ability
Besides speed and scalability, one should also think about what works with which architecture. Several ideas in recent literature are explicitly said to work with ViTs but not with CNNs: "MoCo v3 and SimCLR are more favorable for ViT-B than R50", "This property emerges only when using DINO with ViT architectures, and does not appear with other existing self-supervised methods nor with a ResNet-50", and the patch dropping idea from Masked AutoEncoders is only possible with the plain ViT architecture with non-overlapping patches. For image-text training à la CLIP, both the original CLIP paper and my unpublished experiments show a clearly better performance when using a ViT encoder vs other convolutional encoders, however none of us has a good explanation of why that would be the case. Notably, two of these four references are from Kaiming He, the inventor of ResNets.
Preference
At the end of the day, use whatever works best in your scenario and constraints. Constraints may include things like familiarity or availability of checkpoints. I am not religious about architectures, ViT happens to fit most of my use cases well. The only thing I am religious about, is not making unfounded claims, and calling them out when I see them =)
Acknowledgements: I thank Alexander Kolesnikov and Xiaohua Zhai for feedback on a draft of this post.
If this has been useful to your research, consider citing it:
@misc{beyer2024vitspeed,
author = {Beyer, Lucas},
title = {{On the speed of ViTs and CNNs}},
year = {2024},
howpublished = {\url{http://lb.eyer.be/a/vit-cnn-speed.html}},
}
Footnotes
-
After discussion with Alexander Kolesnikov, we believe this might be an implementation issue in PyTorch (and possibly other frameworks). In principle, for inference, previous activation buffers can be reused in-place as long as they are large enough (in terms of bytes, not shape!), and residuals can be added in-place too. So we believe only two large buffers really need to be held in memory. This is not true for training, however. ↩